What is RDF?
The Resource description framework (RDF) is a data model whose atomic elements are triples. A triple consists of a subject, a predicate and an object.
RDF is the core pillar behind all the Semantic Web technologies.
RDF can be serialized in a number of ways (See W3C Website).
What is Linked Data?
Linked Data is a set of guidelines on how to represent and publish data on the Web. The goal is to facilitate the access to data on the Semantic Web.
Read more about Linked Data on W3C Website
What is the Semantic Web?
The Semantic Web is generally seen as the evolution of the Web (of documents) where data is made available on the Web according the the Linked Data principles and is backed up by the RDF data model (i.e. the semantic Web technologies).
A dataset of the Semantic Web uses HTTP URIs, relies on existing vocabulary, relates to external datasets and uses the RDF data model. Following this, the dataset on Jane could become the following:
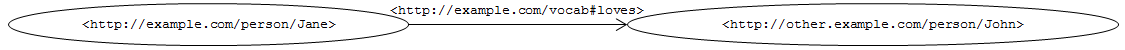
In this example, we consider that Jane is identified in her Website with the URI <http://example.com/person/Jane>. The term <http://example.com/vocab#loves> is defined in a public ontology or repository. Finally, John is identified in his Website with the URI <http://other.example.com/person/John>. The above triple can be represented in TTL (one of RDF's textual representations) with:
<http://example.com/person/Jane> <http://example.com/vocab#loves> <http://other.example.com/person/John> .
What does all of this have to do with product data exchange?
Product data exchange utilizes the Semantic Web technologies (e.g. RDF and all the other related technologies (SPARQL, TTL, OWL...)). However, the principles of Linked Data are not followed because the purpose is not to publish product data on the Web, but to represent product data in a structure that is easy to work with.
Thus, resources are not necessarily identified using HTTP URIs; they may be identified using UUIDs instead. The open-world assumption is not systematic. Finally, it need not rely on vocabulary available on the Web. Example of product data based on the S3KL ontology could be:
<urn:uuid:4ca8b90c-2a34-4982-9b95-c6e7f66306e2> a s3kl:Contract . <urn:uuid:4ca8b90c-2a34-4982-9b95-c6e7f66306e2> s3kl:contractIdentifier "2018-01-09-0AA1" . <urn:uuid:22656d04-87e6-4649-b29f-d97982efd149> a s3kl:Contract . <urn:uuid:22656d04-87e6-4649-b29f-d97982efd149> s3kl:contractIdentifier "2018-01-09-0AA1 WP 1" . <urn:uuid:4ca8b90c-2a34-4982-9b95-c6e7f66306e2> s3kl:contractRelationship_subcontract <urn:uuid:22656d04-87e6-4649-b29f-d97982efd149> .
In this example, we defined two contracts and a relationship to say that contract ID "2018-01-09-0AA1" has a work package in a subcontract.
What is an ontology?
An ontology is a file that describes some semantics on the application data. It is written in RDF. Read the Ontology FAQ to find out more about ontologies.
Is there any software support to sustain all of this?
Absolutely. The Semantic Web community has continued to grow in the past few years. More and more solutions are available, and we have strived to remain vendor-independent so that it's easy to move from one solution to another, or even use several solutions to benefit from complementary characteristics (e.g. reasoning, scalability, environment...).
Our favourite RDF framework is Apache Jena backed by the TDB triplestore. Depending on your needs and settings, you might want to choose different software.